
Últimamente estoy escribiendo bastante sobre Open Data. Si no sabéis lo que es o no estáis familiarizados sobre los catálogos, os recomiendo empezar por la introducción al Open Data y posteriormente sobre la descripción de la arquitectura del Open Data.
También puede resultar interesante una reflexión sobre el gobierno abierto y el open data.
Dentro de la arquitectura del Open Data encontramos un elemento llamado SKOS Concept y ConceptScheme:
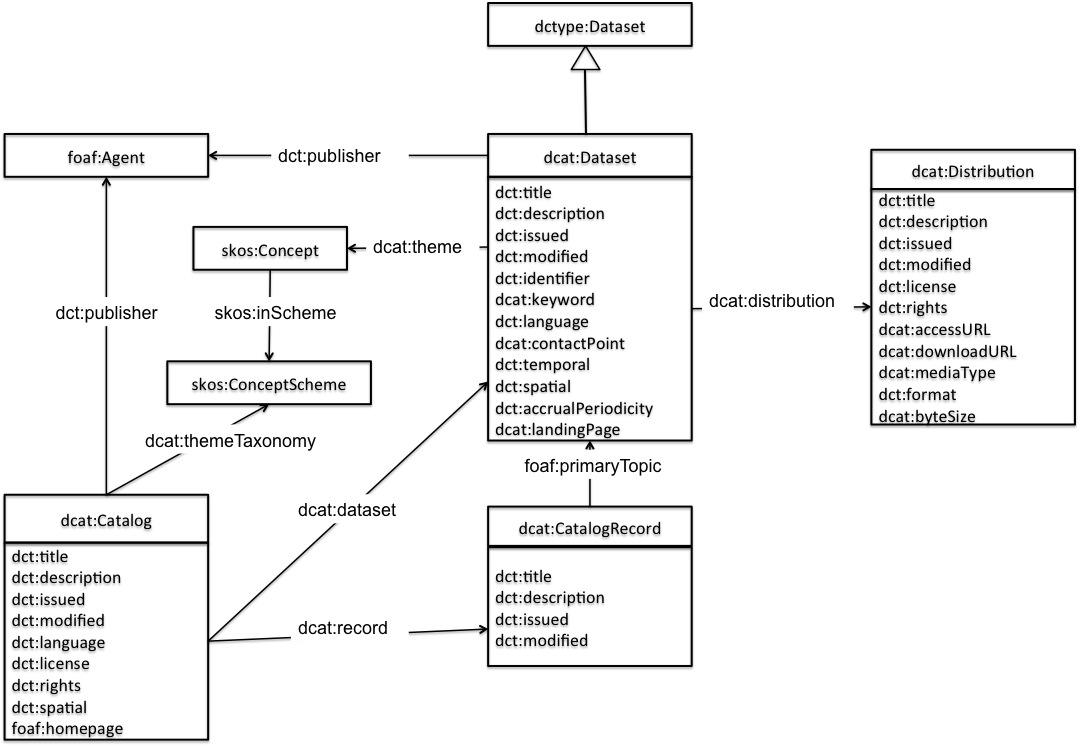
Dado que hay muchas preguntas al respecto, intento introducir SKOS y el Concept y Concept-Scheme.
SKOS son las siglas de Simple Knowledge Organization System o sistema simple de organización del conocimiento. Es un estándar para la definición de la estructura básica y el contenido de esquemas de conceptos como tesauros, esquemas de clasificación, taxonomías, etc. Está construido mediante RDF, que es un framework para definir recursos (‘cosas’ en internet).
Para entender qué es SKOS definamos primero la diferencia entre Vocabulario controlado y Tesauro:
Un vocabulario controlado es una lista de términos que una comunidad u organización ha acordado. Podrían ser por ejemplo los términos referentes a los principios activos de un medicamento: Paracetamol, Amoxicilina, etc.
Una taxonomía es un vocabulario controlado organizado en una jerarquía. Por ejemplo, podemos tener los términos fruta, vegetal y plátano en el cual plátano sería una subclase de fruta, que sería una subclase de vegetal.
Por último, un Tesauro es una taxonomía con más información acerca de cada concepto que incluye términos preferidos y alternativos («Banana» en Inglés, «Plátano» o «Banana» en español). Además un tesauro puede contener relaciones con conceptos relacionados, como las relaciones existentes entre fruta y banana. Básicamente un Tesauro es un diccionario de sinónimos, incluyendo las acepciones en otros idiomas.
Volvamos ahora a SKOS:Concept.
Los conceptos son las unidades de pensamiento las ideas, significados, o los objetos y eventos que subyacen en muchos sistemas de organización del conocimiento. Como tal, existen conceptos como entidades abstractas que son independientes de los términos utilizados para etiquetarlos. En SKOS, un Concept se utiliza para representar los elementos de un sistema de organización del conocimiento (términos, ideas, significados, etc.) o de estructura conceptual o la organización de un sistema de este tipo.
Vamos a aprenderlo con el ejemplo anterior. Creemos el primer concepto SKOS:
ex:Fruta rdf:type skos:Concept.
Hemos creado el Concepto Fruta. Vamos a añadirle información:
ex:Fruta rdf:type skos:Concept; skos:prefLabel "Fruit"@en; skos:prefLabel "Fruta"@es; skos:altLabel "Fruto"@es skos:narrower ex:Vegetal skos:narrower ex:Comida
Aquí estamos definiendo que ‘Fruta’ es un concepto con dos Términos, Fruit (que corresponde al inglés) y Fruta (que corresponde al español). Además, indicamos que es una especialización de dos conceptos: Vegetal y Comida. Por último también le comentamos que «Fruto» es un sinónimo en Castellano
ex:Plátano rdf:type skos:Concept; skos:prefLabel "Banana"@en; skos:prefLabel "Plátano"@es; skos:related ex:Potasio skos:exactMatch ex:Banana
Aquí informamos que Plátano es exactamente igual que el concepto Banana, que podría ser otro concepto . Además, consideramos que el concepto ‘Plátano’ está relacionado con banana.
Un ConceptScheme es, por último, una agrupación de conceptos con sus relaciones.
Espero haber aclarado este complejo ‘concepto’ de SKOS.


